
In the begining I only saw it at WCCFtech with a link to a forum.
But then a lot of sites start to post this as news sooo...
This is the image from http://www.planet3dnow.de/vbulletin/threads/421433-AMD-Zen-14nm-8-Kerne-95W-TDP-DDR4?p=5004014&viewfull=1#post5004014
And the news from different sites:
AMD "Zen" CPU Core Block Diagram Surfaces from TechpowerUp
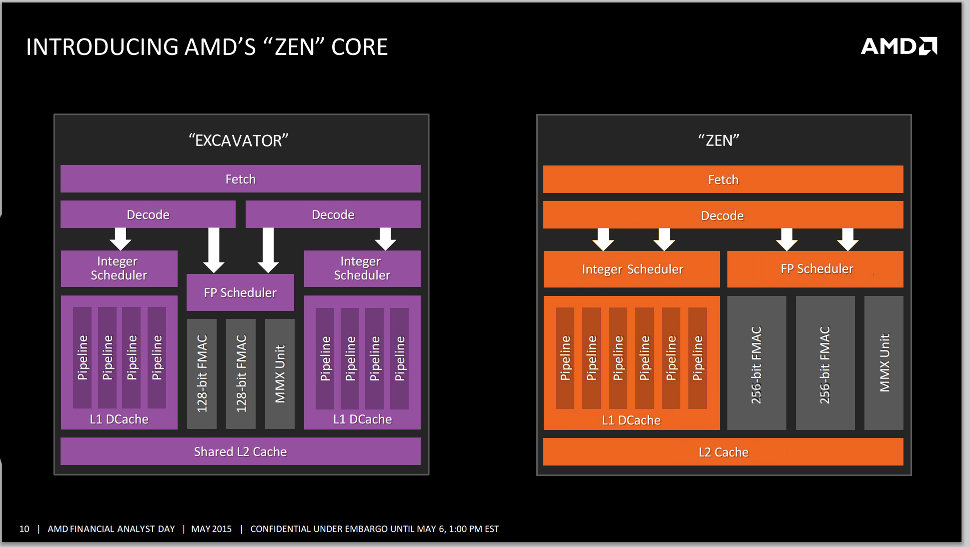
As a quick follow up to our older report on AMD's upcoming "Zen" CPU core micro-architecture being a reversion to the monolithic core design, and a departure from its "Bulldozer" multicore module design which isn't exactly flying off the shelves, a leaked company slide provides us the first glimpse into the core design. Zen looks a lot like "Stars," the core design AMD launched with its Phenom series, except it has a lot more muscle, and one could see significant IPC improvements over the current architecture.
To begin with, Zen features monolithic fetch and decode units. On Bulldozer, two cores inside a module featured dedicated decode and integer units with shared floating-point units. On Zen, there's a monolithic decode unit, and single integer and floating points. The integer unit has 6 pipelines, compared to 4 per core on Bulldozer. The floating point unit has two large 256-bit FMAC (fused-multiply accumulate) units, compared to two 128-bit ones on Bulldozer. The core has a dedicated 512 KB L2 cache. This may be much smaller than the 2 MB per module on Bulldozer, but also indicate that the core is able to push through things fast enough to not need cushioning by a cache (much like Intel's Haswell architecture featuring just 256 KB per core). In a typical multi-core Zen chip, the cores will converge at a large last-level cache, which routes data between them to the processor's uncore, which will feature a DDR4 IMC and a PCI-Express 3.0 root complex.
And A more indepth analysis from PCPerspective:
AMD Zen Diagram Leaked and Analysis
There are some pretty breathless analysis of a single leaked block diagram that is supposedly from AMD. This is one of the first indications of what the Zen architecture looks like from a CPU core standpoint. The block diagram is very simple, but looks in the same style as what we have seen from AMD. There are some labels, but this is almost a 50,000 foot view of the architecture rather than a slightly clearer 10,000 foot view.
There are a few things we know for sure about Zen. It is a clean sheet design that moves away from what AMD was pursuing with their Bulldozer family of cores. Zen gives up CMT for SMT support for handling more threads. The design has a cluster of four cores sharing 8 MB of L3 cache, with each core having access to 512 KB of L2 cache. There is a lot of optimism that AMD can kick the trend of falling more and more behind Intel every year with this particular design. Jim Keller is viewed very positively due to his work at AMD in the K7 through K8 days, as well as what he accomplished at Apple with their ARM based offerings.
One of the first sites to pick up this diagram wrote quite a bit about what they saw. There was a lot of talk about, “right off the bat just by looking at the block diagram we can tell that Zen will have substantially higher single threaded performance compared to Excavator and the Bulldozer family.” There was the assumption that because it had two 256-bit FMACs that it could fuse them to create a single 512 bit AVX product.
These assumptions are pretty silly. This is a very simple block diagram that answers few very important questions about the architecture. Yes, it shows 6 int pipelines, but we don’t know how many are address generation vs. execution units. We don’t know how wide decode is. We don’t know latency to L2 cache, much less how L3 is connected and shared out. So just because we see more integer pipelines per core does not automatically mean, “Da, more is better, strong like tractor!” We don’t know what improvements or simplifications we will see in the schedulers. There is no mention of the front-end other than Fetch and Decode. How about Branch Prediction? What is the latency for the memory controller when addressing external memory?
Essentially, this looks like a simplified way of expressing to analysts that AMD is attempting to retain their per core integer performance while boosting floating point/AVX at a similar level. Other than that, there is very little that can be gleaned from this simple block diagram.
Other leaks that are interesting concerning Zen are the formats that we will see these products integrated into. One leak detailed a HPC aimed APU that features 16 Zen cores with 32 MB of L3 cache attached to a very large GPU. Another leak detailed a server level chip that will support 32 cores and will be seen in 2P systems. Zen certainly appears to be very flexible, and in ways it reminds me of a much beefier Jaguar type CPU. My gut feeling is that AMD will get closer to Intel than it has been in years, and perhaps they can catch Intel by surprise with a few extra features. The reality of the situation is that AMD is far behind and only now are we seeing pure-play foundries start to get even close to Intel in terms of process technology. AMD is very much at a disadvantage here.
Still, the company needs to release new, competitive products that will refill the company coffers. The previous quarter’s loss has dug into cash reserves, but AMD is still stable in terms of cash on hand and long term debt. 2015 will see new GPUs, an APU refresh, and the release of the new Carrizo parts. 2016 looks to be the make or break year with Zen and K12.
TLDR: Phenom III xD
ps: People calculate the 6 int pipelines compare to 4 in buldozer, as 50% performance per core per GHz increase.
That could make it perform at Sandybridge levels of single thread.

If this is true then AMD will be able to compete again at gaming market. Even at high end if they release 16core as they said they will.
ps: For people to understand how bad things are now, if we compare core per core with the same GHz Intel vs AMD at the moment, i7 4790K vs FX8350 (both running at 4GHz), i7 4790K is 72,5% faster than FX8350 in single core performance.



















Log in to comment